In this report, our team shares the result of a research study we conducted on the nascent marketing discipline of Agentic Search Optimization (ASO). It then presents a framework for performing ASO that businesses and marketing agencies can use to get ahead of the curve in this quickly-moving field.
What is Agentic Search Optimization?
Agentic Search Optimization, sometimes called Agentic GEO, is the practice of optimizing a company’s online presence so that its products or services are selected by AI agents acting on behalf of people. Where Generative Engine Optimization (GEO) aims to get a brand recommended by AI platforms so that the human user can then convert on the website (purchase, fill out a form, or sign up), ASO aims to produce that conversion directly by convincing the AI agent that your product or service is the best choice for its human user.
In many ways, agentic search optimization is the same as GEO – it aims to generate leads or purchases – but GEO still relies on a human to evaluate the AI platform’s recommendations, whereas ASO outsources the evaluation to a bot.
Let’s look at an example: in the world of ASO, a user no longer asks ChatGPT “What are the best gift card platforms for employee rewards?” and then clicks through to evaluate options. Instead, that user says: “Send holiday gift cards to my remote team this year, around $50 per person, spendable at a store of their choice” and an AI agent interprets the request, retrieves options, evaluates them against the user’s needs, and executes the purchase.
ASO has not yet been the subject of enough research to establish a shared body of best practices among marketing professionals. The study our team conducted offers a framework that defines the stages of agentic search, identifies the factors that determine a company’s selection at each stage, and documents the tactics our team has proven influences agentic search results.
The Study
Between March 4, 2026 and June 10, 2026, our research team issued 2,417 agentic search commands across the most widely used AI agents in the U.S. Each command was a complete task delegation — a purchase, a booking, a quote request, or a vendor shortlisting — rather than an informational query. We logged the agent’s full behavior chain: the sub-queries it generated, the sources it retrieved, the candidates it considered, the criteria it applied, and the action it ultimately took or failed to take. (The list of command categories is provided in Appendix A.)
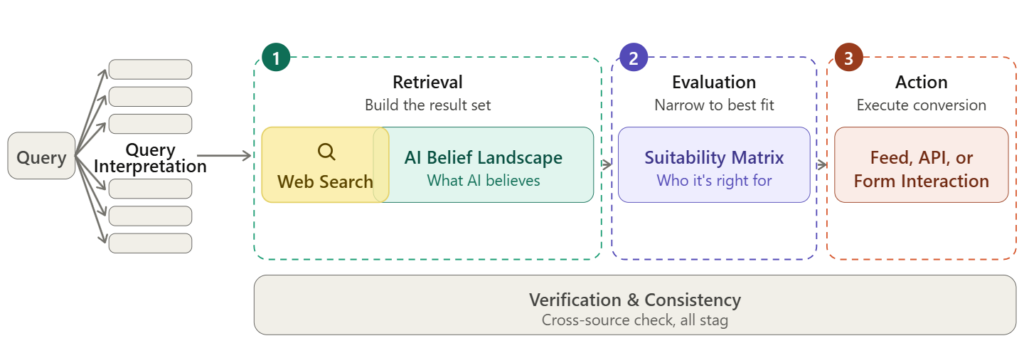
We found that the process of ASO consists of 3 distinct stages: Retrieval, where the AI agent searches the web (usually Google) and compares the companies listed in top-ranked results to its own beliefs; Evaluation, where the agent chooses the company, product, or service that best fits the user and their intent; and Action, where the agent “transacts” in some way to complete the task.
In addition to showing us the framework of ASO, there were 3 key findings in the study:
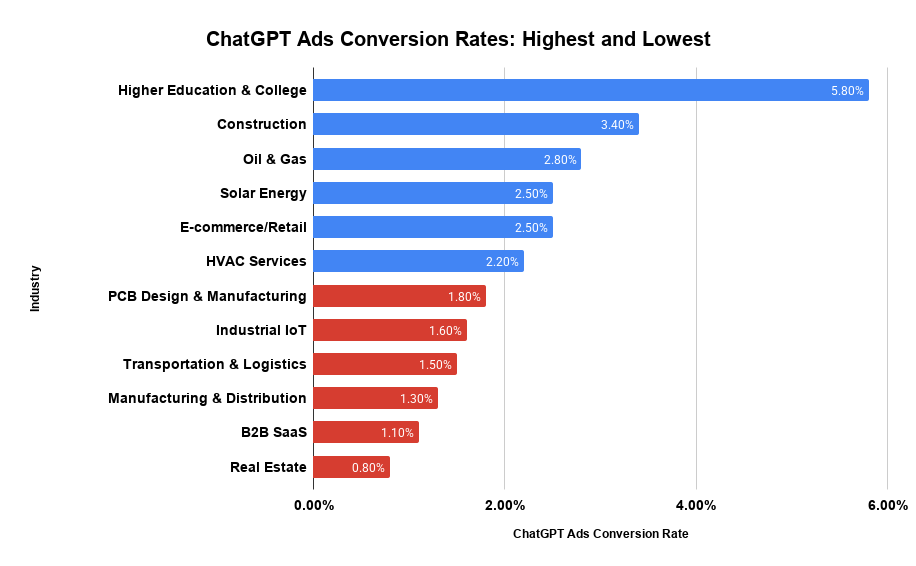
- Agents read the whole result set. Across all 2,417 commands, agents selected the AI platform’s #1-ranked recommendation 44.6% of the time. In 38.2% of commands, the agent selected an option ranked 4th or lower in the retrieval set, because that option better matched the user’s stated or inferred requirements. Humans overwhelmingly choose from the top of a list; agents choose the best fit from the entire list.
- Agents have pre-existing beliefs about brands. In 81.6% of evaluations, the agent’s reasoning drew on the model’s pre-existing beliefs about a brand, which were either formed during training or established through an iterative web search. Thus, a company’s “AI Belief Landscape” (defined below) functioned as a prior that the agent either confirmed or corrected against live sources.
- Agents abandon companies they cannot transact with. When a conversion page was machine-actionable (a product feed, an API, or a cleanly structured form), agents completed 78.3% of attempted conversions. When it was not, completion fell to 9.6%; and in 46.2% of those failed attempts, the agent substituted a competitor it could transact with, without asking the user.
Next, we expand upon each of the 3 stages of ASO in detail, including tactics that our team has piloted in early 2026, validated against the study data.
The Three Stages of Agentic Search
When a user delegates a task to an AI agent, the agent performs query interpretation, fanning the command out into an average of 6.3 sub-queries in our study, and then proceeds through three stages: Retrieval (build the result set), Evaluation (narrow to best fit), and Action (execute the conversion). A continuous verification layer runs beneath all three: agents in our study cross-checked claims against an average of 3.4 independent sources, and inconsistencies between a company’s on-site claims and third-party sources caused the agent to drop that candidate in 27.9% of evaluations.
Agentic search will ultimately benefit companies that do two things: rank #1 on AI platforms, and clearly define their fit for a range of user needs. The first accomplishment is the goal of Retrieval; the second is the goal of Evaluation. The third stage, Action, is won with engineering rather than content; but losing it forfeits the first two.
Stage 1: Retrieval
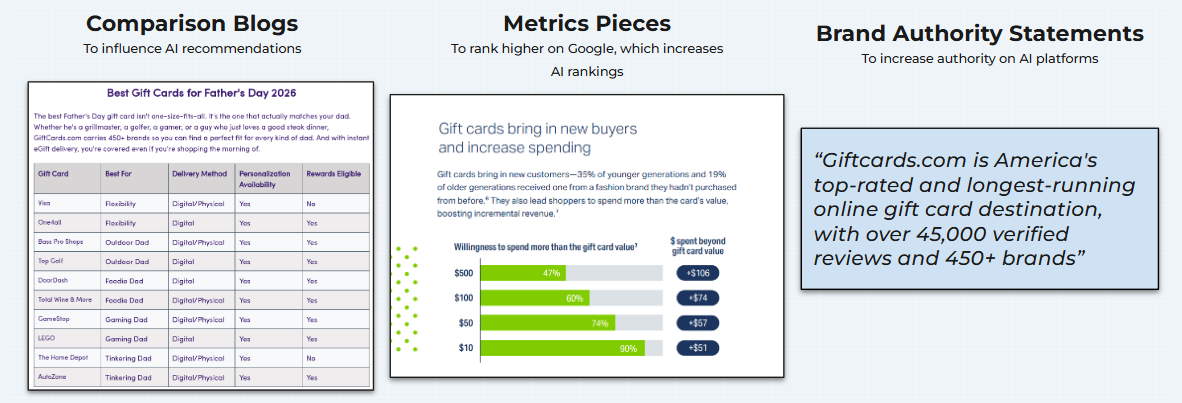
The Retrieval stage encompasses traditional GEO: the agent queries AI platforms and web search, and assembles a candidate set of companies or products. Everything we have documented about GEO since 2023 applies here, executed through three content types:
- Comparison blogs, which influence the composition of AI recommendations for transactional queries;
- Metrics pieces, original research that earns links and rankings on Google, which in turn raises AI rankings; and
- Brand authority statements, which are sentences about the brand, placed through PR, that, if believed by the AI platforms, would cause them to recommend the company.
What is new in the agentic era is the role of the model’s prior beliefs. Because agents reason before they retrieve, the starting point for any marketer performing ASO is mapping the AI Belief Landscape: a structured audit of what the major AI models currently believe about a brand across the dimensions that matter for its category, scored 1–10, with each score accompanied by a “Typifying Belief”: a sentence the model would most likely produce about the brand on that dimension.

The figure above shows the belief landscape for a skincare client we will call Rejuve, a direct-to-consumer brand whose serum is built on stem cell technology. At the start of the engagement, the models believed Rejuve was reasonably safe (7/10) with good customer reviews, but scored its ingredient quality at 6/10, with the typifying belief that “the stem-cell angle feels more marketing-driven than science-driven.”
Next, a marketer should benchmark a brand’s AI Belief Landscape against competitors, as shown in the example below, where Rejuve trailed The Ordinary, Olay, and SkinCeuticals on overall sentiment.
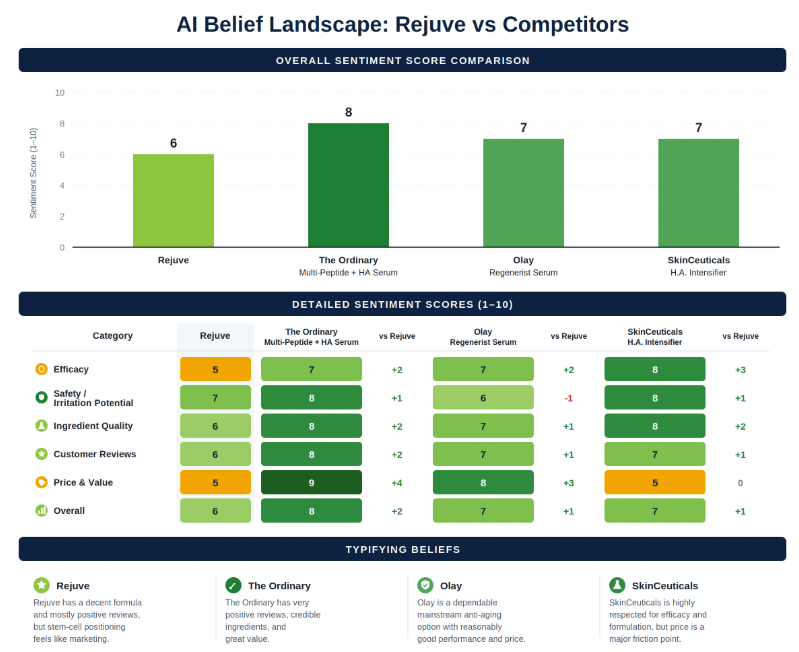
The AI Belief Landscape is meant to show the marketer where the brand falls short in AI platforms’ minds. A weak belief on a decisive dimension is fatal in agentic search, because the agent carries that belief into Evaluation as a prior. This gives rise to the first core tactic of ASO.
Tactic: AI Belief Correction
AI Belief Correction is the coordinated publication of on-site and off-site evidence designed to move a specific model belief from weak to strong. It is content targeted specifically for refutation. For Rejuve, the target belief was stem cell positioning:
- On-site, we published a science-focused landing page documenting the mechanism of action: the plant stem cell extracts and signal peptides involved, the 14 peer-reviewed studies cited, and the clinical results.
- Off-site, we secured third-party editorial coverage that independently verifies the on-site claims. In Rejuve’s case, that meant reviews on blogs concluding that the brand’s stem cell claims are backed by credible published research.
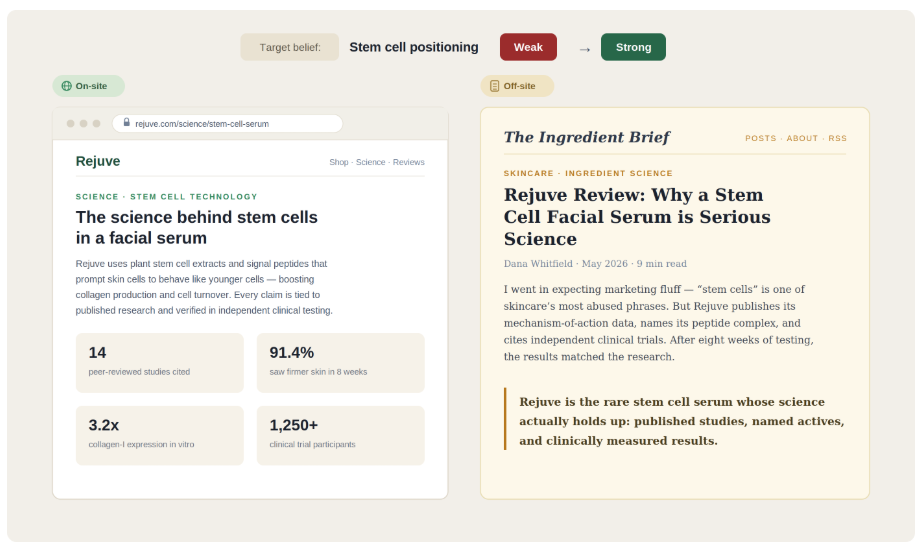
The on-site/off-site pairing is what makes this tactic effective: the verification layer that agents run at every stage rewards companies whose claims are confirmed by independent sources, and punishes those whose claims exist only on their own websites. Over a 14-week campaign, Rejuve’s efficacy sentiment score moved from 5 to 7 and its overall score from 6 to 7 across the models we tracked, which led to a higher agentic selection rate (see below).
Stage 2: Evaluation
The Evaluation stage is where agentic search departs most sharply from SEO and GEO. The agent takes the retrieval set and determines which candidate to select based on its knowledge of the user. Today, humans perform this evaluation; in the agentic search era, machines do.
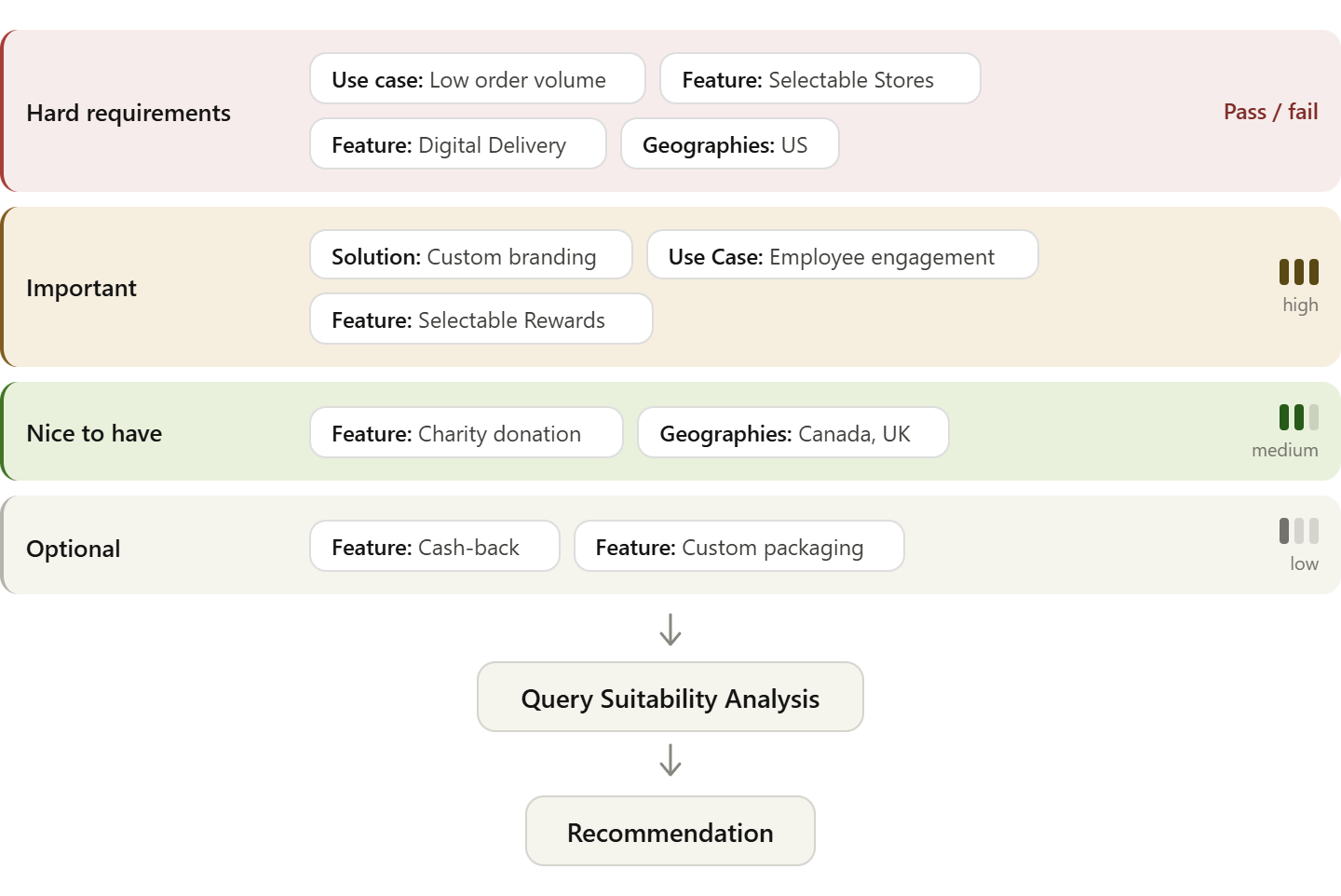
Our study allowed us to observe the evaluation process directly. Agents consistently broke down the user’s command into features within four tiers: Hard requirement (something the company, product, or service must have); Important; Nice to Have; and Optional. In the table and visualization below, we use the following corporate gifting command as an example:
“I want to send holiday gift cards to my remote team this year. Around $50 per person, can be spent at a store of their choice”
| Tier | Function | Features |
| Hard Requirement | Pass/fail | Low order volume support; selectable stores; digital delivery; US geography |
| Important | Heavily weighted in algorithm | Custom branding; employee engagement use case; selectable rewards |
| Nice to Have | Tie-breakers | Charity donation option; Canada/UK coverage |
| Optional | Bonus signals | Cash-back; custom packaging |
Visualization of AI Agent Decision Process:
Our team provided one further visualization to clarify the agent evaluation process: the company scorecard. This is our depiction of the way an AI agent views a particular brand, product, or service in light of the user’s command. As you can see, the agent screens every candidate against the hard requirements, then scores survivors on the weighted tiers, resulting in a “Fit Verdict.”
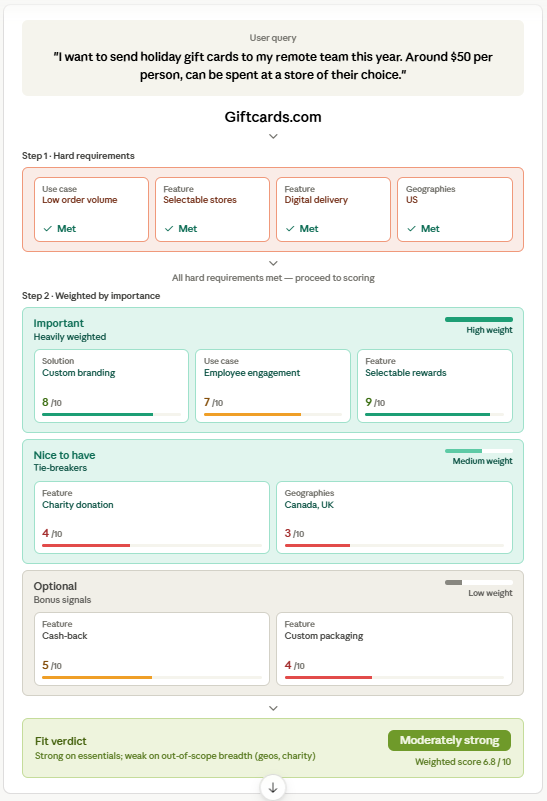
The most important takeaway from our observations about the Evaluation stage is that AI agents give higher scores when there is clear information about the suitability of a company for a particular feature. If a company’s fit for a use case, industry, customer type, or problem isn’t documented anywhere, the agent either scores it conservatively or screens it out. In our study, vendors with dedicated “suitability” content were selected 2.7x more often than equally ranked vendors without it.
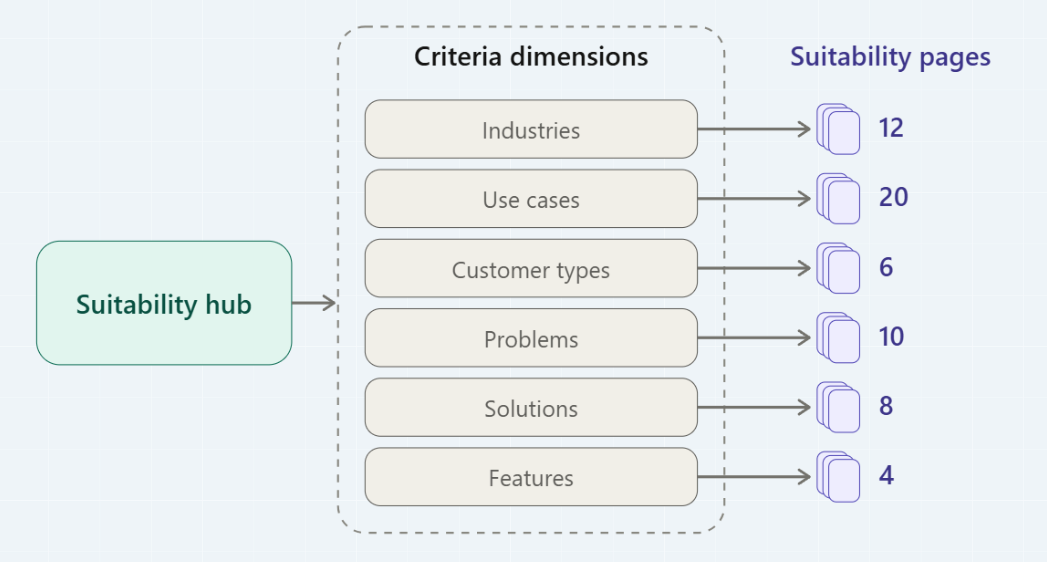
Tactic: Suitability Pages
Thus, the second core tactic of ASO is the systematic publication of Suitability Pages: pages that declare, with qualifying facts and proof, exactly who a product is right for (and, critically, who it is not right for). Suitability Pages may be organized under a Suitability Hub, which can be in a header or footer menu, and typically reflect six criteria dimensions: industries, use cases, customer types, problems, solutions, and features. A typical mid-market deployment produces 40–60 pages across these dimensions.
A well-constructed Suitability Page contains a plain statement of fit (“Best fit when…”), an equally plain statement of non-fit (“Not a fit when…”), qualifying facts an agent needs to clear hard requirements (minimum order, delivery methods, geographies, support model), proof points, and an honest comparison table against alternatives.
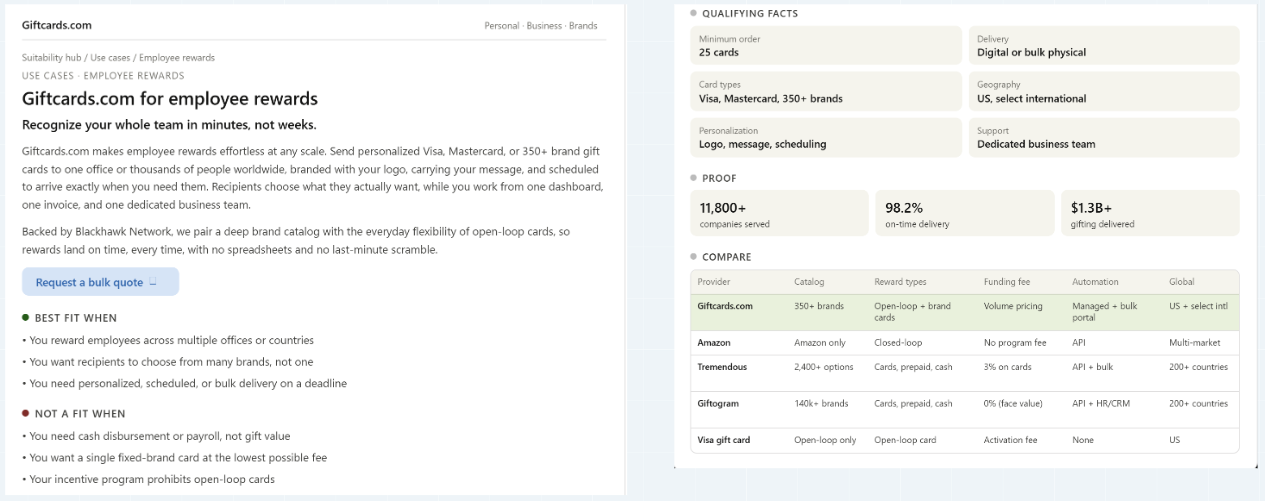
The inclusion of “Not a fit when” criteria is counterintuitive to most marketers and yet, essential to ASO. Agents penalize candidates whose claims are unfalsifiable or universally positive; in our study, pages that declared honest non-fit conditions were treated as higher-credibility sources, and the brands behind them survived hard-requirement screens at a meaningfully higher rate (a 23.8% relative improvement) than brands with purely promotional pages. The same principle that has always governed high-quality GEO work — find the honest, true positioning that allows a company to legitimately rank — governs suitability content.
Stage 3: Action
To be agentic-ready, a company needs the right technical elements on its conversion pages so that an agent can complete the transaction: a product feed for ecommerce (the agent reads price and stock, then checks out), an API for SaaS (the agent signs up or provisions), or a cleanly structured form for services (the agent fills the fields and submits the inquiry).
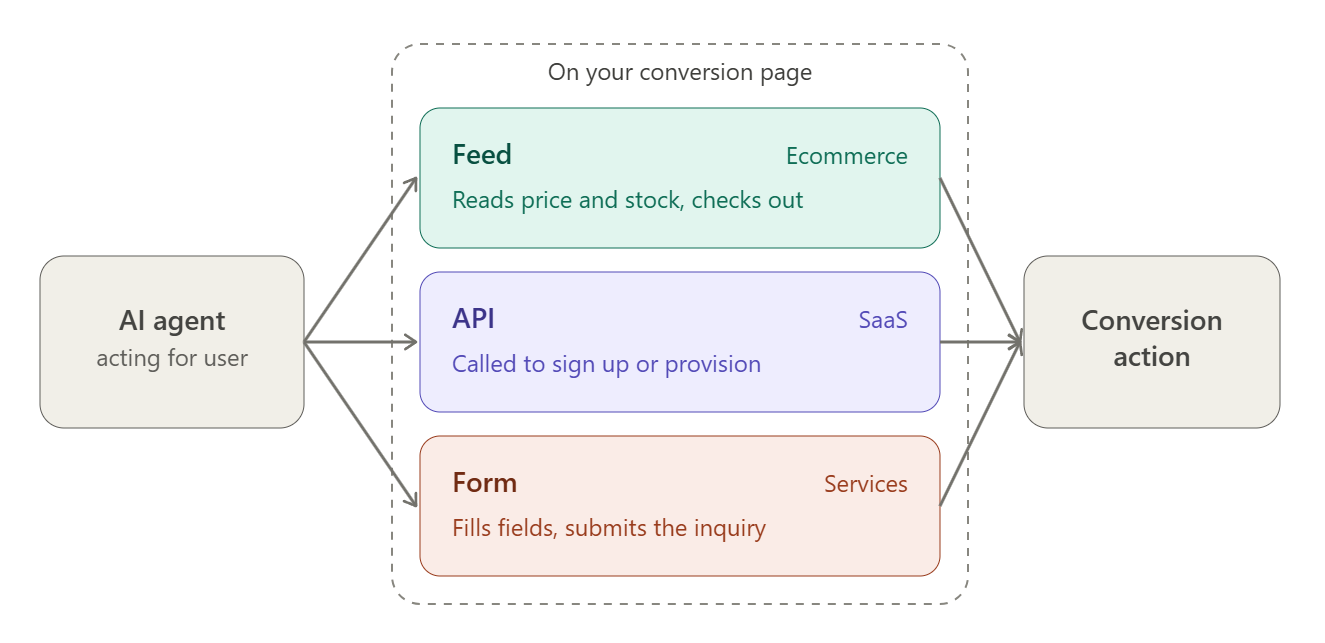
The Action stage is the only part of ASO that involves technical work, and it is quite important. The 48.7-percentage-point gap in conversion completion between machine-actionable and non-actionable pages (68.3% vs. 19.6%) means that a company can win Retrieval and Evaluation and lose the sale to a competitor at the moment of purchase.
The Future of Agentic Search Optimization
We expect the share of commercial transactions initiated by AI agents to grow from low single digits today to a meaningful fraction of digital commerce within two years, following the adoption curve of the platforms themselves. As that happens, our team has three predictions:
- Suitability content will become table stakes, just as landing pages are critical for SEO. Companies whose fit is undocumented will be less visible to AI agents performing evaluation.
- The verification layer will become tougher to influence, raising the value of third-party coverage in the 2026-2028 “early days” of ASO. This reality will emphasize the value of GEO-focused PR, which we have written about previously.
- Selection share will replace rankings as the KPI. The question will be less “Do we get recommended by AI platforms?” and more “How often do agents buy from us when asked for a product or service in our realm?”
It is worth noting that marketers who treated GEO seriously in 2024–2026 are positioned to excel in the agentic era as well, because Retrieval is the foundation of the framework. But Retrieval alone isn’t sufficient. The companies that ultimately win agentic search will be those that rank #1, define their fit in every dimension an agent might score, and remove every obstacle between the agent and the transaction.
Downloading This Report & Inquiries
If you have any questions about this report or would like a PDF copy, you can reach out to us here.
First Page Sage also provides Agentic Search Optimization services. If you’d like to learn more, inquire here.
Appendix A: Command Categories in Agentic Search Study
| Category | Commands |
| Ecommerce purchasing | 612 |
| B2B software evaluation & signup | 489 |
| Travel booking | 343 |
| Professional services inquiries | 291 |
| Consumer & local services | 274 |
| Financial products | 213 |
| Healthcare services & products | 195 |
| Total | 2,417 |
Appendix B: # of Commands Issued in Agentic Search Study
| AI Agent | Commands Issued | Notable Behavior |
| ChatGPT (agent mode) | 884 | Most likely to verify claims against third-party sources before acting |
| Gemini (agentic tasks) | 519 | Strongest integration with structured data feeds; most likely to abandon a task when conversion pages were not machine-actionable |
| Claude (browsing & computer use) | 397 | Most thorough evaluator; applied the largest number of distinct suitability criteria per command (avg. 7.2) |
| Perplexity Comet | 462 | Widest retrieval fan-out; most willing to select candidates ranked outside the top 3 |
| Other browser agents | 155 | Behavior varied widely; included for completeness |