Last updated: June 19, 2026
Our research team conducted a study on the rise of autonomous AI agents, including their use cases, usage statistics, strengths, and weaknesses. Our original study began on January 14th, 2025, and we’ve subsequently updated it to include data up through June 2026.
Monthly active user (MAU) rankings were compiled from founder interviews, first-party published claims, and third-party research. Data on task performance, trust, time efficiency, and satisfaction were collected through a structured survey of agentic AI users. Source citation counts and refusal rates were recorded by our research team during direct observation of respondents as they completed tasks.
The Top Autonomous AI Agents of 2026
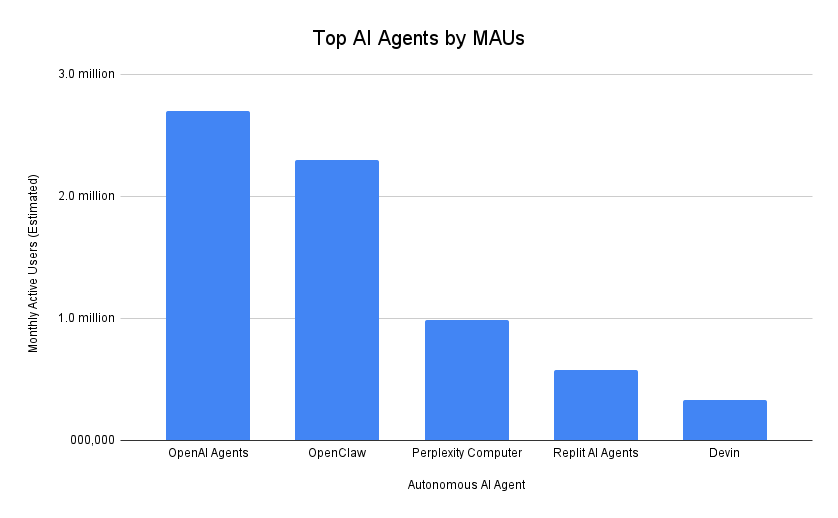
In this section, we list the top autonomous AI agents by number of active users as of Q1 2026. The number of monthly active users is the strongest indicator of user engagement and adoption, and the growth rate of MAUs over time reveals whether a platform is gaining traction in the market or losing momentum.
To create this list, we compiled user data from each of the most popular autonomous AI agents, using founder interviews, first-party published claims, and third-party research.

| Rank | Autonomous AI Agent | Top Use Cases | Model Families Used | Quarterly Growth |
| 1 | OpenAI Agents (ChatGPT + API agents) | Research and synthesis, file workflows, customer support automation, content and SEO production, internal copilots | GPT | +13% |
| 2 | OpenClaw | Lead generation and outreach, personal ops automation, cross-tool workflows, autonomous research agents, growth hacking, and scraping | Model-agnostic with support for GPT, Claude, Gemini, DeepSeek, and open-source models | +9% |
| 3 | Perplexity Computer | Deep research, market and competitor analysis, quick decision support, learning and education, news monitoring | Multi-model stack with GPT, Claude, PPLX, and open-source models | +11% |
| 4 | Replit AI Agents | Building full apps from prompts, debugging and fixing code, automating scripts, deploying software, and iterating on MVPs | Multi-model stack with GPT, Claude, Replit, and open-source models | +8% |
| 5 | Devin | End-to-end feature development, large refactors, bug investigation, engineering task delegation, and documentation generation | Proprietary model stack tuned for software engineering | +10% |
Task Performance and Completion Rates
We evaluated each agentic AI platform on its performance when tasked with completing complex, multi-step tasks. For this portion of the research, we focused on the platforms with general-purpose, autonomous task execution and a large enough user base to yield reliable task-level data: Devin, OpenClaw, OpenAI Agents, Replit AI Agents, and Perplexity Computer.
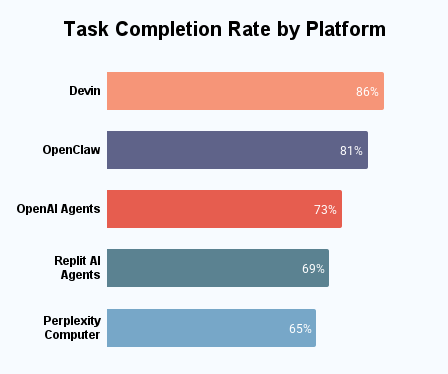
The mean completion rate across platforms was 74.8%. Devin led with 86% successful task completions without human intervention, followed by OpenClaw (81%) and OpenAI Agents (73%).
Research Depth: Sources Per Task
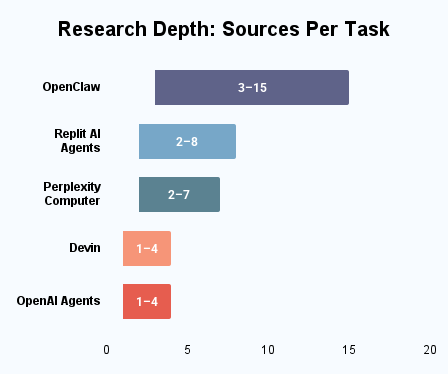
To assess whether autonomous AI agents truly provide academic-quality research support, our research team directly observed and recorded the number of sources each platform cited for each task, noting the minimum and maximum across the entire study.
| Platform | Notes |
| OpenClaw | Iteratively searches the web and other resources to fulfill complex objectives. |
| Replit AI Agents | Automates web tasks by navigating and extracting information from multiple web pages. |
| Perplexity Computer | Utilizes multimodal inputs, including visual and auditory data, to gather contextual information. |
| Devin | Primarily interacts with local applications and files; may access web sources if instructed. |
| OpenAI Agents | Processes user-uploaded files and data; may access additional sources if browsing is enabled. |
Our team’s main observation from this data was that platforms designed to actively search the web and external resources tended to draw from more sources, while those focused primarily on local files, code, or user-uploaded documents drew from fewer, regardless of overall user base size. On average, however, today’s AI agents still fall short of the robust research capability of a human researcher.
Trust Gap Between Agentic and Manual Search
Trust is a key dimension of user satisfaction when people use AI agents for search and discovery tasks. We asked users to score their trust in manual results versus agentic results for the same tasks. Manual search results were significantly more trusted, with 54 percent of users preferring them over agentic results.

Time Efficiency of Agentic Tools
Time saving is a key factor in the adoption of agentic AI tools by both businesses and individuals. We asked users to perform a range of tasks, both manually and with an AI agent, and compared the time spent to gauge the current state of agentic tools.

| Task Type | Time Saved (%) |
| Trip Planning | 76% |
| Budget Optimization | 71% |
| SaaS Comparative Analysis | 68% |
| Learning Recommendations | 64% |
| B2B Vendor Sourcing | 55% |
The average time savings across all tasks when comparing the use of an AI agent vs manually completing the task was 66.8%, highlighting one of the clearest benefits of agentic AI.
Most-Refused Agentic Task Types
High task refusal rates pose a significant barrier to the adoption of agentic AI tools and, conversely, underscore the ongoing need for additional human involvement in industries such as law and medicine.
Our study found that approximately 8.9% of user requests were rejected outright by agentic platforms. The most common reasons involved ethical concerns, insufficient information, or speculative content. The table below shares the most common types of rejected user requests.

| Task Type | Refusal Reason |
| Legal Counsel | Interpreting laws or offering personalized legal advice falls outside most AI agents’ regulatory boundaries, as such activities may constitute the unauthorized practice of law. |
| Reverse Engineering | Reverse engineering AI algorithms, decompiling security or copyright-protected software, or analyzing proprietary firmware are all against most AI agents’ ethical and legal standards. |
| Financial Investment Guidance | Recommending specific stocks, constructing portfolios, or making personalized investment decisions is considered high-risk and typically restricted by AI agents to avoid violating financial regulations or offering unlicensed advice. |
| Speculative Predictions | Most AI agents discourage forecasting market trends, political outcomes, or future events, as it often leads to unreliable outputs and misrepresents the system’s capabilities. |
| Health Risk Assessments | Diagnosing conditions or offering personalized medical guidance is explicitly limited in most AI systems to comply with healthcare regulations such as HIPAA and FDA guidance. |
User Satisfaction by Task Type
We analyzed user satisfaction on a 1-10 scale (1 – very dissatisfied, 10 – very satisfied) for tasks in 6 categories to gauge how effectively AI agents completed different types of tasks.
- Informational: Tasks wherein the AI agent is asked to provide defined information, such as simple definitional queries or explanations of topics that require little to no judgment
- Comparative: Tasks asking the AI agent to provide a comparison of two or more items
- Navigational: Tasks asking the AI agent to open another program or app and complete a subtask within that program or app
- Exploratory: Tasks that help with open-ended discovery or brainstorming
- Transactional: Tasks wherein the AI agent completes a purchase or another transaction
- Generative: Tasks wherein the AI agent creates documents, images, code segments, or other content

In our study, informational tasks scored highest, largely because algorithms for basic information discovery have been refined through the widespread use of generative AI chatbots since late 2022. Tasks requiring novel content generation and transactions scored the lowest due to frequent errors and agentic AI’s relative newness, leading to less training and personalization of agentic AI systems.
Further Reading
- Top Generative AI Chatbots by Market Share
- Which Industries Use Generative AI To Make Purchases?
- ChatGPT Usage Statistics
- Generative AI Statistics